MatchUp Hub#
MatchUp® Hub is where you can find key details about all MatchUp information better understand the minutiae of MatchUp across all of our MatchUp product line.
Essentials#
Distribution Comparisons#
MatchUp Windows Desktop |
MatchUp Object |
MatchUp ETL |
|
|---|---|---|---|
Matchcode Editor |
✓ |
✓ |
✓ |
Programming Required |
✓ |
||
Multi-Platform |
✓ |
||
Real-Time Deduping |
✓ |
||
Flexible Output |
Various File Types |
Various File Types |
|
Record Limit |
Unlimited |
Unlimited |
Unlimited |
Global Processing |
US, CAN, UK |
Global |
Global |
Output Record Consolidation |
Gathering |
Survivorship |
|
Output Record Priority |
Priority |
Golden Record |
|
Source Record Update (Distribute) |
Scattering |
||
Rapid Development |
✓ |
✓ |
|
Rapid Integration |
✓ |
||
Direct File Handling |
✓ |
✓ |
|
Unlimited Files |
✓ |
Source, Lookup |
|
Analyzing |
Built-in Tool |
||
File Control Toolset |
✓ |
||
CASS |
✓ |
||
Automatic Reports Generated |
18 Reports |
||
Updates |
CASS |
✓ |
✓ |
Support |
✓ |
✓ |
✓ |
Distribution Options#
Troubleshooting#
Establishing Benchmarks#
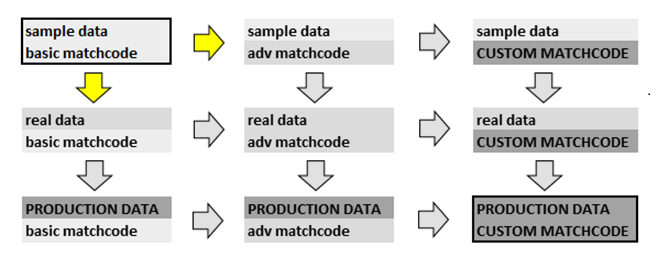
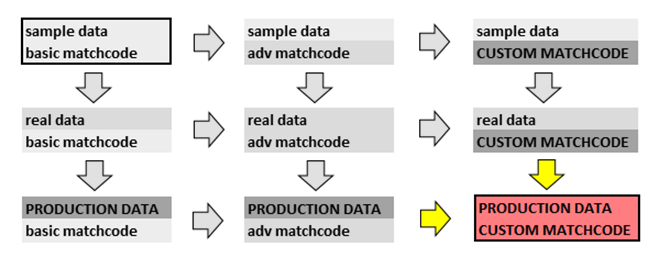
Migrating from Proof of Concept to Production Deployment
The purpose of the establishing a benchmark – before proceeding to live production data and custom matchcodes is to establish that the said requirements will be possible in your environmment.
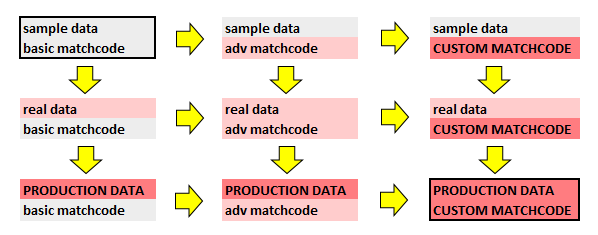
For this reason, we have provided a 1 million record benchmarking file to establish that your environment will most likely not cause slow performance when moving forward. In each benchmarking case.
The benchmark should be established running the sample data local with respect to the local installation, use the recommended default matchcode, and should not use available advanced options.
Download MatchUp Benchmark Data:
ftp://ftp.melissadata.com/SampleCodes/Current/MatchUp/mdBenchmarkData.zip
For MatchUp Object, we have provided sample benchmarking scripts. For ETL solutions, benchmarks should use the following configured settings, which simulate the most basic usage of the underlying object. And also represents the first step in a Proof of Concept to Production migration….
A simple file read, MatchUp keybuilding, deduping and output result stream will be established as the lone Data Flow operation…
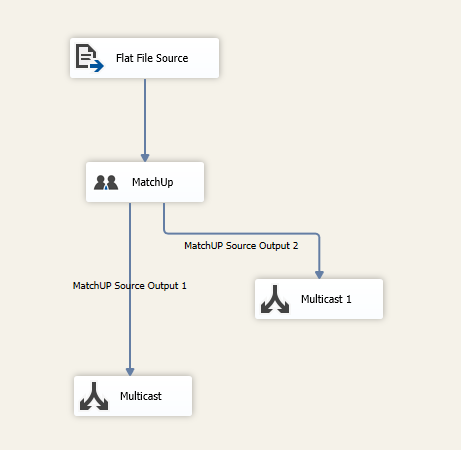
All distributions of MatchUp provide the benchmark matchcode…
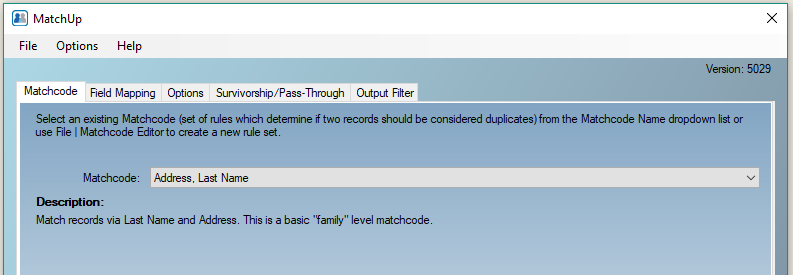
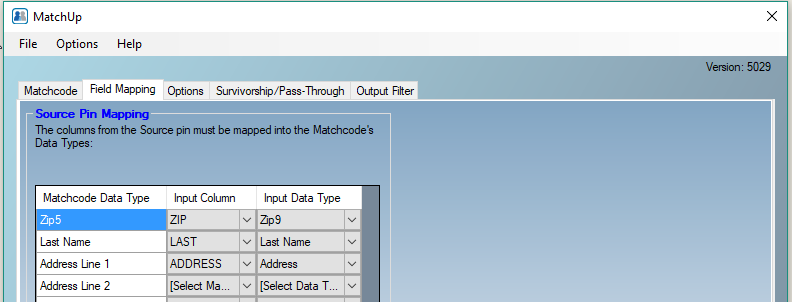
Basic input Field Mapping should be checked…
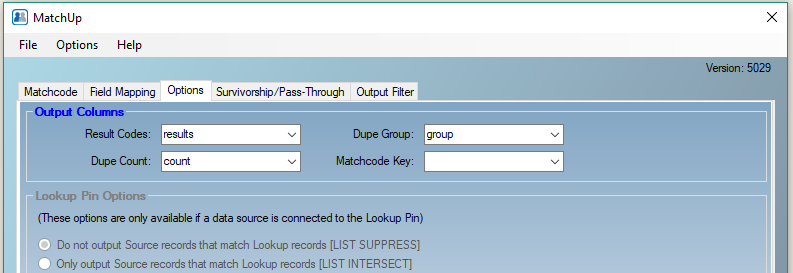
Force generation of important output properties compiled during a MatchUp process, although we’ll evaluate only the Result Code property to get Total record and Duplicate counts…
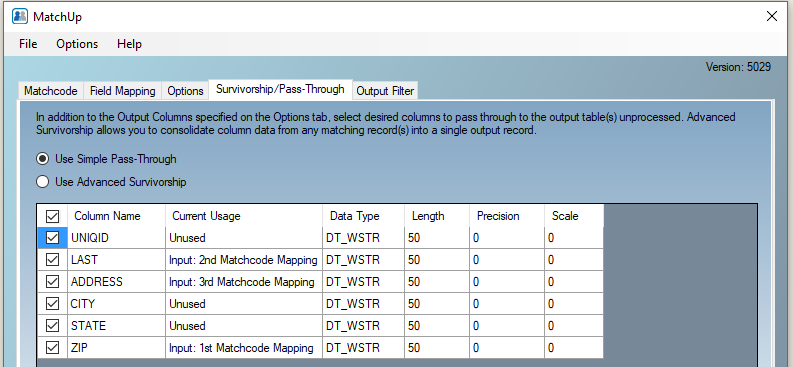
Although configuring Pass-Through options for all source data fields should have a negligible effect on our benchmarking, it should be noted that in actual production, Passing a large amount of source data and or Advanced Survivorship can slow down a process considerably….
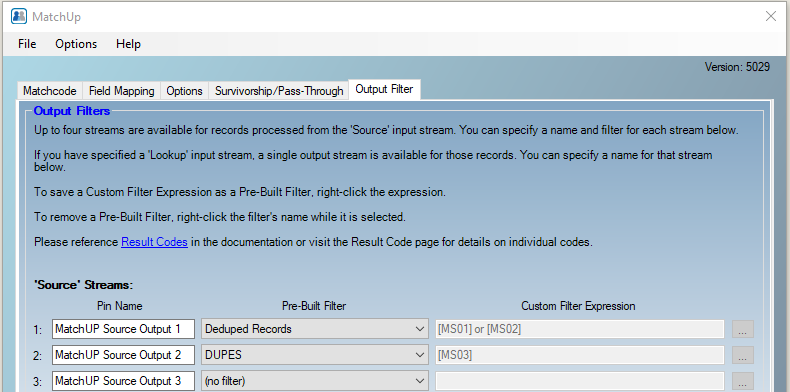
We’ll create two output streams that will allow us to tally the Total and Duplicate counts….
After the benchmark program has been configured and successfully run, you are ready to make small incremental steps…
If returned benchmark results do not closely resemble the expected benchmarks provided by Melissa, please fill and return the Benchmark form and return to Melissa. Completeness and additional comments provided can help eliminate current or potential performance issues when the process is scaled up to resemble a production process.
MatchUp Benchmark Form
ftp://ftp.melissadata.com/SampleCodes/Current/MatchUp/MatchUpBenchmarkForm.dotx>
Matchcode Optimization#
Evaluate Matchcode#
To help you understand the effect of constructing and implementing a sub-optimal matchcode, the Evaluate Matchcode feature evaluates the five critical areas of a matchcode which determine whether one can expect the best throughput when running a process. Evaluate matchcode will indicate if your matchcode is optimized, has a warning, or is sub optimal.
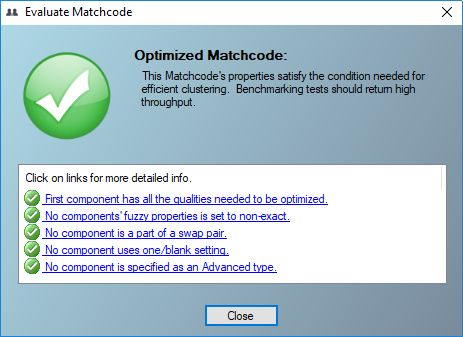
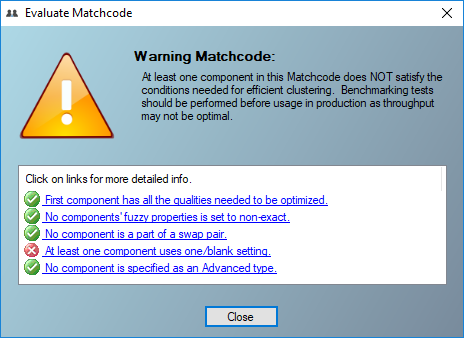
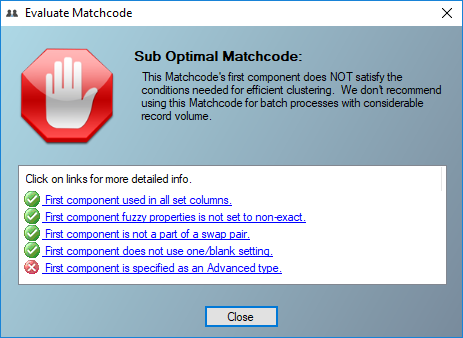
Five Critical Matchcode Areas#
First Component Used in All Set Columns#
When the first component is not checked (not evaluated) in all used combinations, processing will be very slow, as matchkeys cannot be grouped by that first component into optimal neighborhood clusters.
Concepts for Efficient Matching: First Component Combinations
Summary#
Once a workflow is tested to be stable and secure, the two most important concerns for data processing engineers when implementing a process in production are
Throughput – How fast will it take to process the data?
Accuracy – Does the output meet the expectations for accuracy?
Choosing the right matching strategy for MatchUp seeks to satisfy both criteria, but in many cases a trade-off must be made as more granular matching strategies required to detect inexact records as duplicates come at a cost of processing speed, or record throughput.
During processing, a matchcode key is generated as a representation for each record, to be compared to the keys of other records. Ideally, every record’s key would be compared to every other record’s key. This, however, is not practical in all but very trivial applications because the number of comparisons grows geometrically with the number of records processed. For example, a record set of 100 records requires 4,950 comparisons (99 + 98 +…). A larger set of 10,000 records requires 49,995,000 comparisons (9,999 + 9,998 +…). Large record sets would take prohibitive amounts of time to process.
Specifics: Clustering#
To give you a mechanism to process large amounts of data and reduce comparisons without affecting accuracy, MatchUp uses the concept of neighborhood sorting, or clustering, to place records in sub groups of potential matches, thus cutting the total number of comparisons during the deduping process.
In many cases, this will be all or part of the ZIP/Postal Code. So what MatchUp does is only compare records that are (in this example) in the same ZIP or Postal Code. On the average (in the US, using 5-digit ZIP codes), this will cut the average number of comparisons per record by a factor of thousands. This requires that the zip code component is enabled in all used columns (or matchcode conditions).
This concept is known as break grouping, clustering, partitioning, or neighborhood sorting. It is very likely that most, if not all other deduping programs have used some form of clustering method.
Here is an example set of matchcode keys using ZIP/Postal Code (5 characters), Last Name(4), First Name(2), Street Number(3), Street Name(5):
02346BERNMA49 GARD
02346BERNMA49 GARD
02357STARBR18 DAME
02357MILLLI123MAIN
03212STARMA18 DAME
When the deduping engine encounters this set of matchcode keys, it compares all the keys in “02346” (2 keys), then “02357” (2 keys), and finally “03212” (1 key). For this small set, 10 comparisons are turned into 2.
In reality, MatchUp’s clustering engine is a bit more complicated than this, but this description will aid in understanding its mechanics.
If the second component in the matchcode is also configured in all used matchcode combinations this increases the number of characters in a records matchkey which can be used to sub-divide, or cluster, records into more efficient sub-groups and further reduce the number of comparisons.
A second deduping engine, the Intersecting deduper, allows you to create matching strategies with rule sets completely independent of each other. This eliminates having to run multiple passes, but with a great speed penalty, and is recommended only for real time deduping or very small data sets.
Examples#
Often when users have unverified and or incomplete addresses, they set up a logically accurate but very slow matching strategy:
Component |
Size |
Fuzzy |
Blank |
1 |
2 |
3 |
4 |
|---|---|---|---|---|---|---|---|
ZIP/PC |
5 |
No |
Yes |
X |
X |
||
City |
12 |
No |
Yes |
X |
X |
||
State |
2 |
No |
Yes |
X |
X |
||
Street # |
5 |
No |
Yes |
X |
X |
||
Street Name |
5 |
No |
No |
X |
X |
||
PO Box |
10 |
No |
No |
X |
X |
||
Last Name |
5 |
No |
Yes |
X |
X |
X |
X |
A customer use case shows that verifying your addresses can allow you to turn a 58 hour process into a 4 hour process, by satisfying first component combination conditions:
Component |
Size |
Fuzzy |
Blank |
1 |
2 |
|---|---|---|---|---|---|
ZIP/PC |
5 |
No |
Yes |
X |
X |
Street # |
5 |
No |
Yes |
X |
|
Street Name |
5 |
No |
No |
X |
|
PO Box |
10 |
No |
No |
X |
|
Last Name |
5 |
No |
Yes |
X |
X |
Since there’s another component which also satisfies first component combination conditions, dragging it up in the matchcode component order can make the process run even faster – without changing the logic in identifying duplicates.
Component |
Size |
Fuzzy |
Blank |
1 |
2 |
|---|---|---|---|---|---|
ZIP/PC |
5 |
No |
Yes |
X |
X |
Last Name |
5 |
No |
Yes |
X |
X |
Street # |
5 |
No |
Yes |
X |
|
Street Name |
5 |
No |
No |
X |
|
PO Box |
10 |
No |
No |
X |
Fuzzy Settings#
If a component uses a fuzzy algorithm other than exact, each record compared will produce speed penalty on keybuilding or on that algorithms required computation when deduping.
Fuzzy Algorithms#
MatchUp has an extensive list of fuzzy algorithm choices. Depending on the nature of the data being processed, selecting a specific algorithm may result in more flagged duplicates, but possibly with the tradeoff of a slower throughput. This is called balancing performance vs accuracy. The fuzzy algorithms, with a general performance rank from fastest (5) to slowest (1):
ALGORITHM |
RANK |
LATE or EARLY |
|---|---|---|
5 |
Early |
|
5 |
Early |
|
5 |
Early |
|
5 |
Early |
|
5 |
Early |
|
4 |
Early |
|
4 |
Early |
|
4 |
Late |
|
3 |
Late |
|
3 |
Late |
|
3 |
Late |
|
2 |
Late |
|
2 |
Late |
|
2 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
|
1 |
Late |
These algorithms fall into two categories: early matching and late matching.
Early Matching#
Early matching algorithms are algorithms where a string is transformed into a (usually shorter) representation and comparisons are performed on this result. In MatchUp, these transformations are performed during key generation, which means that the early matching algorithms pay a speed penalty once per record: as each record’s key is built.
Late Matching#
Late matching algorithms are actual comparison algorithms. Usually one string is shifted in one direction or another, and often a matrix of some sort is used to derive a result. These transformations are performed during key comparison. As a result, late matching algorithms pay a speed penalty every time a record is compared to another record. This may happen several hundred times per record.
Matching Speed#
Therefore, late matching is much slower than early matching. If a particular matchcode is very slow, changing to a faster fuzzy matching algorithm may improve the speed, and often will give nearly the same results. Test thoroughly before processing live data.
Accuracy#
Using an Exact fuzzy setting will return a logical Boolean answer based on the matchkey – the two keys are either ‘Exactly’ the same and therefore match, or are not exactly the same, and therefore do not match. Fuzzy algorithms make allowances for un-exact data.
Since each algorithm calculates the variation allowance differently, some algorithms perform more accurately over others for differently constructed data
In choosing an algorithm with respect to accuracy, consider the following types of data:
Value Type cases for Fuzzy Algorithm usage
String : % similarity between two strings.
Knowledgebase: The presence of keys words (HS v High School) must be evaluated.
Dictionary (or decode) Arrays: “01 03 46 82” vs “06 46 03 01”.
Value types where fuzzy algorithms are not recommended
Quantifiable: numbers, dates, phone values, account numbers, etc.
Use cases where fuzzy algorithms are not recommended
Record consolidation: Gather, Survivorship, record roll-up.
Pro and con recommendations are made in each algorithms page.
In many cases the algorithm output has been normalized so the return value can be compared against the user configured distance threshold percentage.
Swap Matching#
When each key is compared, swapping one records values (for example: an inverse name format) and reattempting to identify a match will produce slower processing speeds.
See Swap Matching Uses for more details.
Summary#
Swap matching is used to catch matches when two field values are flipped around. The most common occasion is catching the “John Smith” and “Smith John” records, or when the database contains multiple phone or email fields.
Returns#
A match if configured for ‘Both’ components or configured as ‘Either’ component matches where ‘Both’ is defined as a match when both values match before being flipped, or when both values match after the second record has its field values flipped.
‘Either’ is defined as match when either of the two values match before being flipped, or when either of the two values match after the second record has its field values flipped.
Examples#
Example Matchcode Usage 1

Example Data 1
STRING1 |
STRING2 |
RESULT |
|---|---|---|
John |
Smith |
Match Found |
Smith |
John |
Match Found |
Example Matchcode Usage 2

Examlpe Data 2
STRING1 |
STRING2 |
RESULT |
|---|---|---|
781-660-0004 |
Match Found |
|
781-640-7777 |
781-660-0004 |
Match Found |
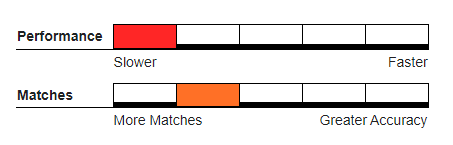
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Small batch runs, or larger batch runs when higher listed matchcode components have efficiently grouped records by clustering and therefore reduced the number of records that need to have swapping attempted.
Not Recommended For#
Large or Enterprise level batch runs. Since the swapping must be evaluated for each record comparison, throughput will be very slow. Each swapping attempt takes a late speed hit similar to when using a fuzzy algorithm.
Blank Matching#
Allowing one of the 2 values being compared to either be blank or a single initial will require the matchup engine to make an extra comparison(s) and will produce a speed penalty.
See Blank Field Matching for more details.
Summary#
Sometimes it is desirable to create a matchcode that will prevent matches when two compared values are present and unique, but allow the match when one of the values is blank or an initial abbreviation. Enabling Short/Empty options determine blank value behavior.
Returns#
A match if the value is the same, or if its blankness or initial satisfies the configured match conditions.
Examples#
Example Matchcode Usage 1

Example Data 1
FIRST |
LAST |
RESULT |
|---|---|---|
John |
Smith |
Match Found |
J |
Smith |
Match Found |
Smith |
Match Found |
|
Mary |
Smith |
Unique |
Example Matchcode Usage 2

Example Data 2
LAST |
ADDRESS |
RESULT |
|---|---|---|
Smith |
12 Main St apt 3 |
Match Found |
Smith |
12 Main St |
Match Found |
Smith |
12 Main St apt 2 |
Unique |
Smith |
12 Main St |
Match Found |
In both of the above examples, the unmatched record could have been found as (and indeed could be) a match to one of the other ‘one-blank’ records. But the previously processed short record had already been placed into another duplicate group.
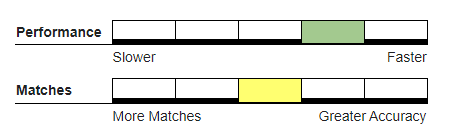
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Small batch runs where the actual number of blank values is minimal.
Not Recommended For#
Batch processes where the number of records which may be grouped together and may contain short or blank values is great. The above examples demonstrate that MatchUp has to at some point make a decision as to which group a blank value really matches. By default, the order in which incoming records are processed determine whether a record will be added to an existing group or create a new dupe group.
Advanced Matchcode Component Type#
Most matchcode component types simply specify how to extract source data into a records matchkey, but Advanced types will also tell the deduping engine to perform a calculation foreach record compared, even if the Distance property is set to zero.
Specifics#
See Matchcode Components for more details.
Summary#
Most matchcode component data types specify the format of the source data, and any advanced operations that need to be performed on that component are specified in its properties. There are three exceptions, which also require a unit range of variance that will still constitute a match:
Date (days)
Numeric (units)
Proximity (miles)
Returns#
A match if the distance between two records being matched is within the configured range.
Examples#
Example Matchcode Usage 1

Example Data 1
NAME |
DATE |
RESULT |
|---|---|---|
John |
19980422 |
Match Found |
John |
19980426 |
Match Found |
John |
20181107 |
Unique |
Example Matchcode Usage 2

Example Data 2
COMPANY |
EMPLOYEES |
RESULT |
|---|---|---|
Wilson Elec |
640 |
Match Found |
Wilsons |
15 |
Match Found |
Wilson Corp |
623 |
Match Found |
Example Matchcode Usage 3

Example Data 3
LATITUDE |
LONGITUDE |
RESULT |
|---|---|---|
33.63757 |
-117.6073 |
Match Found |
33.637466 |
-117.609415 |
Match Found |
33.650388 |
-117.837956 |
Unique |
Performance#
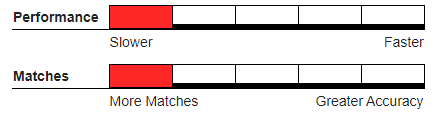
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Small batch runs or larger batch runs when higher listed matchcode components have efficiently grouped records by clustering and therefore reduced the number of records that need to have the unit difference math performed.
Not Recommended For#
Large or enterprise level batch runs. Since the proximity must be evaluated for each record comparison, throughput will be very slow. Each swapping attempt takes a late speed hit similar to when using a fuzzy algorithm.
Algorithms#
Accunear#
Specifics#
Accurate Near is a Melissa Algorithm largely based on the Levenshtein Distance Algorithm.
Summary#
A typographical matching algorithm. You specify (on a scale from 1 to 4, with 1 being the tightest) the degree of similarity between data being matched. This scale is then used as a weight which is adjusted on the length of the strings being. Because the algorithm creates a 2D array to determine the distance between two strings, results will be more accurate than Fast Near at expense of throughput.
Returns#
Boolean ‘match’ if the normalized distance between two strings is less than the configured scale, where distance is defined as the count of the number of incorrect characters, insertions and deletions.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Maguire |
Mcguire |
Match Found |
Deanardo |
Dinardio |
Unique |
34-678 Core |
34-678 Reactor |
Unique |
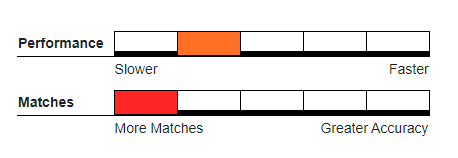
Recommended Usage#
This works best in matching words that don’t match because of a few typographical errors and where the accuracy in duplicates caught outweighs performance concerns.
Not Recommended For#
Gather/scatter, Survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to Matchup with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Alphas#
Specifics#
Only alphabetic characters will be compared.
Summary#
This algorithm will remove all characters that are not in the English alphabet and compares strings based on this criteria.
Returns#
Returns a match is all alphabetic characters match exactly.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Lynda |
Dylan |
Unique |
Apco Oil Lube 170 |
Apco Oil Lube 342 |
Match |
Thomas |
Tom |
Unique |
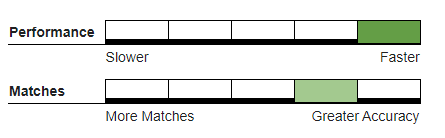
Recommended Usage#
Hybrid Deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Consonants#
Specifics#
Only consonants will be compared. Vowels will be removed. ‘Y’ is defined as a vowel in this algorithm.
Summary#
This algorithm removes vowels from the string and compares two strings based on their consonants.
Returns#
Returns a match if two strings’ consonants match exactly.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Ron Doe |
Ron Doe67 |
Match |
Lynda |
Dylan |
Unique |
Tim |
Tom |
Match |
Brian |
Ian |
Unique |
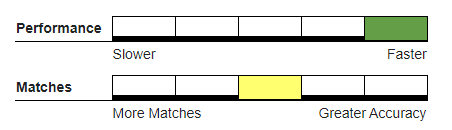
Recommended Usage#
Hybrid Deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
Database where disemvoweling was used to reduce storage space (https://en.wikipedia.org/wiki/Disemvoweling).
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Containment#
Specifics#
Matches when one record’s component is contained in another record.
For example, “Smith” is contained in “Smithfield.”
Summary#
This algorithm looks at the record’s component and determines whether that component is contained in the record it is attempting to match.
Returns#
Returns true if one record’s component is contained in another record.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Mild Hatter |
Mild Hatter Wks |
Match |
Smith |
Smithfield |
Match |
Melissa |
Eli |
Match |
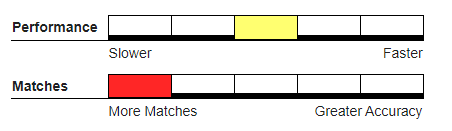
Recommended Usage#
Hybrid Deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Batch or Enterprise runs where the first component allows efficient clustering.
Databases where unrecognized keyword variations appear in some of the records.
When the entire value or string of one is contained in the other.
Not Recommended For#
Short name string comparison.
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Dice’s Coefficient#
Specifics#
Summary#
Like Jaro, Dice counts matching n-Grams (discarding duplicate NGRAMs).
Returns#
Percentage of similarity
2 * (commonDiceGrams) / (dicegrams1 + dicegrams2)
NGRAM is defined as the length of common strings this algorithm looks for. Matchup’s default is NGRAM = 2. For “ABCD” vs “GABCE”, Matching NGRAMS would be “AB” and “BC”.
dicegramsX is defined as the number of unique NGRAMS found in stringX.
commonDiceGrams is defined as the number of common NGRAMS between the two strings.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Maguire |
Mcguire |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Apco Oil Lube 170 |
Apco Oil Lube 342 |
Match Found |
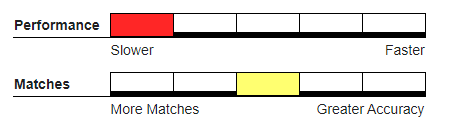
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created with abbreviations or similar word substitutions.
Not Recommended For#
Large or Enterprise level batch runs. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Databases created via real-time data entry where audio likeness errors are introduced.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Double Metaphone#
Specifics#
Double Metaphone improves upon the Soundex algorithm by identifying inconsistencies in English spelling and pronunciation to produce a more accurate encoding.
Summary#
A variation of both the Soundex and Phonetex algorithms. Double Metaphone performs 2 different Phonetex-style transformations. It creates two Phonetex-like strings (primary and alternate) for both strings based on multiple phonetic variations which originated from other languages. Unlike Soundex and Phonetex, the Metaphones are generated during the comparison algorithm.
Returns#
Primary keys match = 99.9%
Alternate keys match = 85.0%
Primary matches alternate = 85.0%
Alternate keys match = 75.0%
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Deanardo |
Dinardio |
Match Found |
Beaumarchais |
Bumarchay |
Match Found |
Theverymost |
Hteberynost |
Unique |
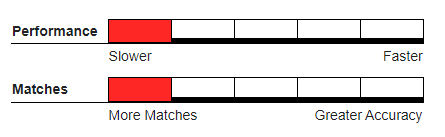
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
Large or Enterprise level batch runs. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Fields whose content data is of type Dictionary or Quantifiable.
Databases of non-US and non-English language origin.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Exact#
Specifics#
Determines whether two values are identical.
Summary#
Two values are compared against each other and determined to be a match if they are exactly the same.
Returns#
Returns a match if two values are exactly the same.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Smith |
Smith |
Match |
Beaumarchais |
Bumarchay |
Unique |
Deanardo |
Dinardio |
Unique |
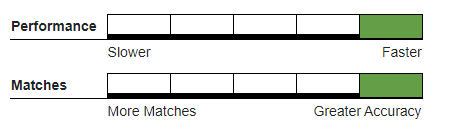
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Batch processes where NGRAM is set on a single non-first matchcode component.
Databases created with abbreviations or similar word substitutions.
Multi word field data where a trailing word does not appear in every record in the expected group or data contains acceptable variations of one of the keywords.
Not Recommended For#
Databases where the number of errors with relation to the string length result is a small number of common substrings.
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Fast Near#
Specifics#
Fast Near is a Melissa algorithm loosely based on the Levenshtein Distance Algorithm, which returns the distance between two strings, where distance is defined as the count of the number of incorrect characters, insertions, and deletions.
Summary#
A typographical matching algorithm, Fast Near works best in matching words that don’t match because of a few typographical errors. The user specifies (on a scale from 1 to 4, with 1 being the tightest) the degree of similarity between data being matched. The scale is then used as a weight which is adjusted on the length of the strings being. The Fast Near algorithm is a speedy approximation of the Accurate Near algorithm.
Returns#
Boolean ‘match or no match’ based on whether the compared data has less than an adjusted number of differences (or more).
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Maguire |
Mcguire |
Match Found |
Deanardo |
Dinardio |
Match Found |
34-678 Core |
34-678 Reactor |
Unique |
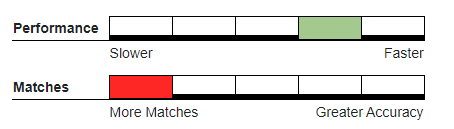
Recommended Usage#
Batch processing: this is a fast algorithm which will identify a greater percentage of duplicates found than other algorithms, but since it is more basic in its routine, sometimes Fast Near will find false matches or miss true matches.
Not Recommended For#
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Frequency#
Specifics#
The Frequency algorithm will match the characters of one string to the characters of another without any regard to the sequence.
Summary#
Frequency can be used when 2 strings are expected to have the same characters and are of the same length.
For example, “abcdef” would be considered a 100% match to “badcfe.” But should not be used to match a variant number of characters. For example “wxyz” would not match “wzy” nor “wzzy”
Returns#
Boolean ‘match’ if the compared data has the same values.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Johnson |
Johnosn |
Match Found |
Lynda |
Dylan |
Match Found |
A B D H T |
A T B H D |
Match Found |
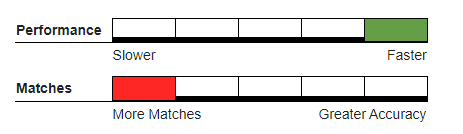
Recommended Usage#
Batch processing—this is a fast algorithm which will identify a greater percentage of duplicates because it will count exact matches and minor character transpositions.
This algorithm is also recommended when the data is comprised of single character dictionary values like ‘A B C’.
Not Recommended For#
Short name data types where a simple character transformation would represent a different value.
This algorithm is also not recommended when trying to identify differences in long strings.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Frequency Near#
Specifics#
The Frequency near algorithm will match the characters of one string to the characters of another without any regard to the sequence while allowing a set number of differences.
Summary#
Frequency Near can be used when 2 strings are expected to have the same characters, but might be transposed or have an insertion or deletion. For example “abcdef” would be considered a 100% match to “badcfe” or “badcfx”.
Returns#
Boolean ‘match’ if the compared data has the same values.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match |
Lynda |
Dylan |
Match |
A B D H T |
A T H D X |
Match |
A B D H T |
A T H D B |
Match |
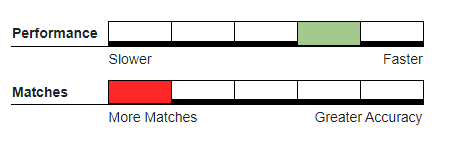
Recommended Usage#
Batch processing—this is a fast algorithm which will identify a greater percentage of duplicates because it will count exact matches and minor character transpositions.
This algorithm is also recommended when the data is comprised of single character dictionary values like ‘A B C’.
Not Recommended For#
Short name data types where a simple character transformation would represent a different value.
This algorithm is also not recommended when trying to identify differences in long strings.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Jaccard Similarity Coefficient#
Specifics#
Jaccard Index
Summary#
Jaccard Similarity Index is defined as the size of the intersection divided by the size of the union of the sample sets.
Returns#
Percentage of similarity
Intersection/ Union
NGRAM is defined as the length of common strings this algorithm looks for.
Matchup default is NGRAM = 2. For “ABCD” vs “GABCE”, Matching NGRAMS would be “AB” and “BC”.
Intersection is defined as the number of common NGRAMS and union is the total number of NGRAMS
in the universe of the two strings.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Mild Hatter |
Mild Hatter Wks |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Apco Oil Lube 170 |
Apco Oil Lube 342 |
Match Found |
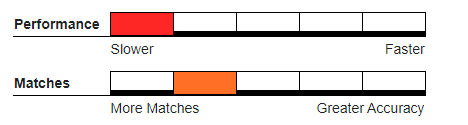
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created with abbreviations or similar word substitutions.
Not Recommended For#
Large or Enterprise level batch runs. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Databases created via real-time data entry where audio likeness errors are introduced.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Jaro#
Specifics#
Winkler Distance
Summary#
Gathers common characters (in order) between the two strings, then counts transpositions between the two common strings.
Returns#
Percentage of similarity
1/3 * (common/len1 + common/len2 + (common- transpositions)/ common)
Where common is defined as a character match if the distance within the 2 strings is within the algorithms defined range.
Transpositions are defined as: a character match (but different sequence order) /2
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Maguire |
Mcguire |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Deanardo |
Dinardio |
Unique |
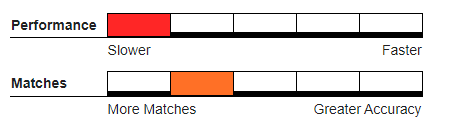
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created with abbreviations or similar word substitutions.
Not Recommended For#
Large or Enterprise level batch runs. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Databases created via real-time data entry where audio likeness errors are introduced.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Jaro-Winkler#
Specifics#
Winkler Distance
Summary#
Like Jaro, JaroWinkler gathers common characters (in order) between the two strings, but adds in a bonus for matching characters at the start of the string (up to 4 characters). Then counts transpositions between the two common strings.
Returns#
Percentage of similarity
Jaro + WinklerFactor * WinklerScale * (1-Jaro)
WinklerFactor is defined as the length of common prefix at the start of the string up to a maximum of four characters.
WinklerScale is a constant scaling factor for adjusting the common Winkler factor.
MatchUp uses the commonly used standard of 0.1.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Stephenz |
Stevens |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Apco Oil Lube 170 |
Apco Oil Lube 342 |
Match Found |
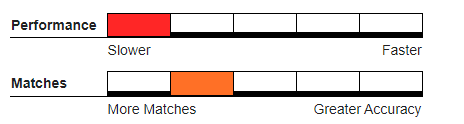
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created with abbreviations or similar word substitutions.
Multi word field data where a trailing word does not appear in every record in the expected group.
Not Recommended For#
Large or Enterprise level batch runs where the matchcode component using this algorithm prevents efficient clustering. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Databases created via real-time data entry where audio likeness errors are introduced.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Longest Common Substring (LCS)#
Specifics#
Finds the longest common substring between the two strings.
Summary#
This algorithm finds the longest common substring between two values.
For example, the longest common substring between “ABCDE” and “ABCEF” is “ABC”
Returns#
lenLCS/ maxLen
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Abcd |
Abce |
Match |
Abcde |
Abcef |
Unique |
Ron Doe |
Ron Doe67 |
Match |
Al Doe Aerostructures Co |
Ad Aerostructures Co |
Match |
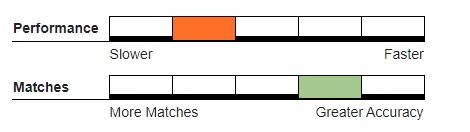
Recommended Usage#
Hybrid Deduper - Where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Batch or Enterprise runs where the first component allows efficient clustering.
Databases where unrecognized keyword variations appear in some of the records.
General or Company data that contain a large similar string but have slight variations in valid keywords and company acronyms cannot accurately be built
Not Recommended For#
Short name string comparison.
Gather / scatter, Survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to Matchup with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
MD Keyboard#
Specifics#
An algorithm developed by Melissa which counts keyboarding mis-hits.
Summary#
This is a typographical matching algorithm which counts keyboarding mis-hits with a weighted penalty based on the distance of the mis-hit and assigns a percentage of similarity between the compared strings. Thus two records with c > v or v > b typos are more likely to have an actual duplicate.
Returns#
Percentage of similarity
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Neumon |
Pneumon |
Match Found |
Hteberynost |
Theverymost |
Match Found |
Covert |
Coberh |
Match Found |
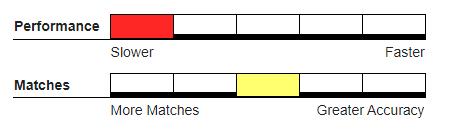
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Batch processes where MDKEY is set on a single non-first matchcode component.
Databases where data entry is created real-time from call center or other inputs where keyboard mishits are more likely.
Not Recommended For#
Databases where the number of errors with relation to the string length result is a small number of common substrings.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Needleman-Wunsch#
Specifics#
Summary#
A typographical matching algorithm, and a variation of the Accurate Near and Levenshtein algorithms. Levenshtein and Needleman-Wunsch are identical except that character mistakes are given different weights depending on how far two characters are on a standard keyboard layout.
For example: A to S is given a mistake weight of 0.4, while A to D is a 0.6 and A to P is a 1.0. Because the algorithm creates a 2D array to determine the distance between two strings, results will be more accurate than Fast Near at expense of throughput.
Returns#
Boolean ‘match’ if the normalized distance between two strings is less than the configured scale, where distance is defined as the count of the number of incorrect characters, insertions, and deletions.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Maguire |
Mcguire |
Match Found |
Deanardo |
Dinardio |
Unique |
Dearobier |
Des Robiere |
Match Found |
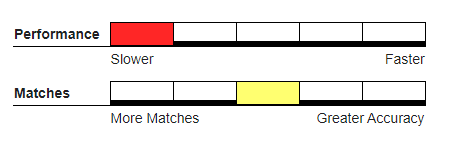
Recommended Usage#
Hybrid or real-time deduping.
This works best in matching words that don’t match because of a few typographical errors and where the accuracy in duplicates caught outweighs performance concerns.
Not Recommended For#
Enterprise size processes.
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
N-Gram#
Specifics#
Summary#
Counts the number of common contiguous sub-strings (grams) between the two strings.
Returns#
Percentage of similarity
MatchingGrams/(LongestLength – (NGRAMS - 1))
NGRAM is defined as the length of common strings this algorithm looks for.
Matchup default I NGRAM = 2. For “ABCD” vs “GABCE”, Matching NGRAMS would be “AB” and “BC”.
MatchingGrams is the count of the number of matching grams.
LongestLength is the longer string length of the two strings being compared.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Neumon |
Pneumon |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Apco Oil Lube 170 |
Apco Oil Lube 342 |
Match Found |
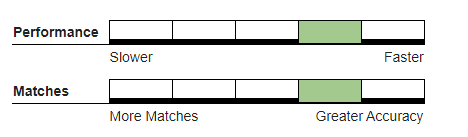
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Batch processes where NGRAM is set on a single non-first matchcode component.
Databases created with abbreviations or similar word substitutions.
Multi word field data where a trailing word does not appear in every record in the expected group or data contains acceptable variations of one of the keywords.
Not Recommended For#
Databases where the number of errors with relation to the string length result is a small number of common substrings.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Numeric#
Specifics#
Only numeric characters will be compared.
Summary#
This algorithm only compares numeric values. All characters and strings will be discarded.
Returns#
Returns a match if the values’ numeric characters match exactly.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
34-678 Core |
34-678 Reactor |
Match |
Apco Oil Lube 170 |
Apco Oil Lube 230 |
Unique |
12345 |
12345 |
Match |
2468 |
1357 |
Unique |
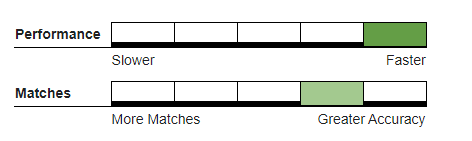
Recommended Usage#
Hybrid Deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Not Recommended For#
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Overlap Coefficient#
Specifics#
Summary#
Like Jaro or Dice, counts matching n-Grams (discarding duplicate NGRAMs), but uses a slightly different calculation weighted towards the smaller of the two strings being compared.
Returns#
Percentage of similarity
Union/ MinNumNGrams
Where union is defined as the number of matching NGAMS found
Where minNumNGrams is defined as the smallest number of possible NGRAMS of the two strings
NGRAM is defined as the size of the substring to search for within a string (default is 2).
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Neumon |
Pneumon |
Match Found |
Maytown Hs |
Maytown Public Schools |
Match Found |
Rober |
Roberts |
Match Found |
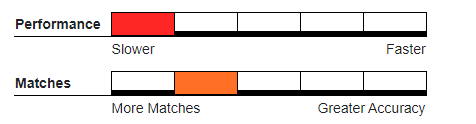
Recommended Usage#
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created with abbreviations or similar word substitutions.
Not Recommended For#
Large or Enterprise level batch runs. Since the algorithm must be evaluated for each record comparison, throughput will be very slow.
Databases created via real-time data entry where audio likeness errors are introduced.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Phonetex#
Specifics#
(pronounced “Fo-NEH-tex”) An auditory matching algorithm developed by Melissa. It works best in matching words that sound alike but are spelled differently. It is an improvement over the Soundex algorithm.
Summary#
A variation of the Soundex Algorithm. Phonetex takes into account letter combinations that sound alike, particularly at the start of the word (such as ‘PN’ = ‘N’, ‘PH’ = ‘F’).
Returns#
The Phonetex algorithm is a string transformation and comparison-based algorithm and is performed on the keybuilding.
For example, JOHNSON would be transformed to “J565000000” and JHNSN would also be transformed to “J565000000” which would then be considered a Phonetex match after evaluation.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Stephenz |
Stevens |
Match Found |
Beaumarchais |
Bumarchay |
Match Found |
Neumon |
Pneumon |
Match Found |
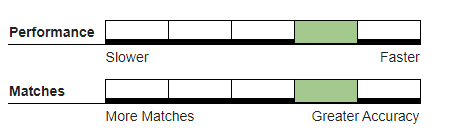
Recommended Usage#
Large or enterprise level batch runs where. Using this algorithm will not prevent efficient clustering. Since the algorithm is performed during keybuilding, throughput will be fast.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
Databases of non-US and non-English language origin.
Fields whose content data is of type Dictionary or Quantifiable.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Smith-Waterman-Gotoh#
Specifics#
Summary#
A typographical matching algorithm. A variation of the Needleman-Wunch, where it gives a non-linear penalty for inserts and deletes, but less of a penalty for linear inserts and deletes.
For example, JNSON has 0.8+0.8 = 1.6 penalty in Needleman-Wunch, but only a 0.8+0.6 = 1.4 penalty in Smith-Waterman-Gotoh. This effectively adds the ‘understanding’ that the keyboarder may have tried to abbreviate one of the words. Because the algorithm creates a 2D array to determine the distance between two strings, results will be more accurate than Fast Near at expense of throughput.
Returns#
Boolean ‘match’ if the normalized distance between two strings is less than the configured scale, where distance is defined as the count of the number of incorrect characters, insertions and deletions.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Mild Hatr Wks |
Mild Hatter Works |
Match Found |
Deanardo |
Dinardio |
Unique |
Apco Quik Lube |
Apco Quik Oil N Lube |
Match Found |
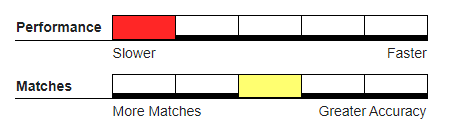
Recommended Usage#
Hybrid or real-time deduping. This works best in matching where the data entry has a proprietary abbreviation rule set.
Not Recommended For#
Enterprise size processes.
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Soundex#
Specifics#
Summary#
An auditory matching algorithm originally developed by the Department of Immigration in 1917 and later adopted by the USPS. Although the Phonetex algorithm is more accurate, the Soundex algorithm is presented for users who need to create a matchcode that emulates one from another application.
Returns#
The Soundex algorithm is a string transformation and comparison-based algorithm and is performed on the keybuilding.
For example, JOHNSON would be transformed to “J525” and JHNSN would also be transformed to “J525” which would then be considered a Soundex match after evaluation.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Match Found |
Stephenz |
Stevens |
Match Found |
Beaumarchais |
Bumarchay |
Match Found |
Neumon |
Pneumon |
Unique |
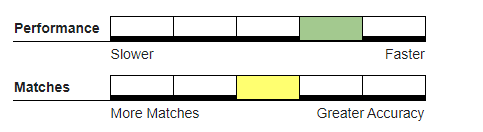
Recommended Usage#
Large or enterprise level batch runs where using this algorithm will not prevent efficient clustering. Since the algorithm is performed during keybuilding, throughput will be fast.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
For real-time data entry where audio likeness errors can be introduced and accuracy is of the utmost importance, we recommend Phonetex for greater accuracy.
Databases of non-US and non-English language origin.
Fields whose content data is of type Dictionary or Quantifiable.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
UTF8 Near#
Specifics#
An algorithm developed by Melissa to match multi-byte data.
Summary#
UTF-8 Near is meant to perform general distance (or string similarity) comparisons as an alternative to the other available algorithms which are designed to evaluate strings on a character for character basis.
For many international extended character sets, a character cannot be represented by a single byte, and therefore makes results returned by those algorithms inaccurate.
Returns#
Percentage of similarity
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Maguire |
Mcguire |
Match Found |
Beaumarchais |
Bumarchay |
Unique |
Asbjørn Aerocorp |
Asbjorn Aerocorp |
Match Found |
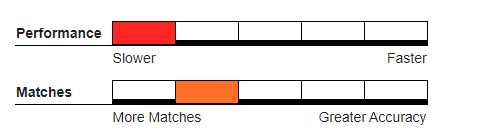
Recommended Usage#
UTF-8 data. This algorithm was added to MatchUp with the assumption that international data contains multi-byte characters, making other algorithms inconsistent in accuracy for usage.
Hybrid deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database. Batch level runs where other matchcode components are set to exact or databases of a single country origin.
Not Recommended For#
Databases merged from different countries and intended to match on a single data type.
Vowels#
Specifics#
Only vowels will be compared. Consonants will be removed. ‘Y’ is defined as a vowel in this algorithm.
Summary#
This algorithm removes consonants from the string and compares two strings based on their vowels.
Returns#
Returns a match if two strings’ vowels match exactly.
Example Matchcode Component#

Example Data#
STRING1 |
STRING2 |
RESULT |
|---|---|---|
Johnson |
Jhnsn |
Unique |
Lynda |
Dylan |
Match |
Smith |
Smith |
Match |
Brian |
Ian |
Match |
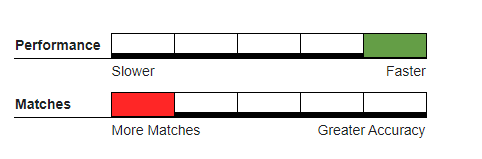
Recommended Usage#
Hybrid Deduper, where a single incoming record can quickly be evaluated independently against each record in an existing large master database.
Databases created via real-time data entry where audio likeness errors are introduced.
Databases of US and English language origin.
Not Recommended For#
Gather/scatter, survivorship, or record consolidation of sensitive data.
Quantifiable data or records with proprietary keywords not associated in our knowledgebase tables.
Do Not Use With#
UTF-8 data.
This algorithm was ported to MatchUp with the assumption that a character equals one byte, and therefore results may not be accurate if the data contains multi-byte characters.
Programming Environment#
Have the Latest Build#
Have the latest Build of the respective Melissa Solution.
We always recommend users use the most current build (version), which may contain new or improved features, code fixes, or updated functionality. Melissa provides many ways to ensure you keep your components to the latest version.
Run on a Local Instance#
VM support#
Network Speed#
Proprietary network configurations can vary greatly, therefore preventing us from making universal recommendations. The Best Practice is to run MatchUp as a local Installation of the application (calling program) with respect to the source data location. If your production environment requires independent application location with regard to source data, we recommend you first create local benchmarks and migrate to a production configuration -testing thoroughly along the way.
Memory management#
It goes without saying that the more hardware – a faster processor, additional memory and a fast disk drive will produce faster throughput than a lesser machine. The MatchUp data files are loaded into memory but given their size with respect to common memory configurations, memory considerations are negligible. Your source data is not loaded into memory as a typical source database can be in the GB range.
Process Work Files#
As MatchUp processes your database, it produces a matchkey for each record, sorts the keys for efficient deduping, and for some distributions, such as the ETL solutions, must keep track of source pass thru data. Using the default installation settings, these files will be located here:
C:\Users\MyUserName\AppData\Local\Temp
The work files are in the format of:
myKeyFileName.key - Key File Example
md29F8.002 - Temporary Sort File Example
mpAB6.tmp - Passthrough File Example
This is the temp directory of the logged in User. For *nix platforms, the directory where the executable is being ran.
Although users can override this location, we do not recommend it, unless you are pointing this location to a fast, local drive with plenty of writable disk space and full read write permissions.
ETL: SSIS, Pentaho#
VM#
Known Issues - SQL Server 2016 Compatibility with VMWare
Please avoid utilizing the option Hot Swap CPU when hosting with SQL Server 2016 with VMWare. We discovered that this is against the best practices from VMWare (3.3.6 CPU Hot Plug). Engineers from both VMware and Microsoft has verified that this will lead to issues with thread contention. The setting MAXDOP if set to too high will also have an effect on the contention and SSIS processes/our components may hang especially with our Matchup Component.
As reported from our client, reports show that when querying SQL Server Numa in DMV (sys.dm_os_memory_nodes) only one node will be allocated 100% memory. After disabling Hot Swap CPU, SQL Server now correctly detects a single numa. Disabling Hot Swap CPU will increase performance and should prevent hanging issues from occurring in SSIS.
This Hot Swap CPU issue is only reported for SQL Server 2016 edition, which we may think is caused by the new cardinality estimator and automatic soft numa default features. The combination of new changes and incorrect setup in VMware may have caused the thread waits past a certain threshold.
SQL Server File Names vs Versions#
File Name |
SQL Server |
Version Number |
|---|---|---|
80 |
SQL Server 2000 |
8.00.xxxx |
90 |
SQL Server 2005 |
9.00.xxxx |
100 |
SQL Server 2008 |
10.00.xxxx |
105 |
SQL Server 2008 R2 |
10.50.xxxx |
110 |
SQL Server 2012 |
11.00.xxxx |
120 |
SQL Server 2014 |
12.00.xxxx |
130 |
SQL Server 2016 |
13.00.xxxx |
140 |
SQL Server 2017 |
14.00.xxxx |
150 |
SQL Server 2019 |
15.00.xxxx |
Having a file with one of these names does not mean you have the corresponding SQL Server installed. Some files can be installed by newer versions of SQL Server, Visual Studio, and other tools.
To find your currently installed version of SQL Server:
Go to Start Menu
Select the newest version of Microsoft SQL Server 20xx
Select Menu
Select Configuration Tools > SQL Server Configuration Manager
Select the SQL Server Services tab
Sort by Service Type
For each SQL Server type:
Right-Click the SQL Server item
Select Properties
Select the Advanced tab
Find the Version field.
This is the Microsoft SQL Server sub directory where the SSIS installer will install the MatchUp component and processor libraries.
What Versions of SQL Server/Visual Studio are Supported?#
Using an unsupported version may no longer produce stable processing.
Melissa currently supports SQL Server versions 2012, 2014, 2016 and 2017. We also provide components for SQL Server 2005, 2008 and 2010 as part of the SSIS Installation, however, they are no longer supported.
Certain Microsoft SQL Server version are officially supported by specific Microsoft Visual Studio versions for our components. BusinessCoder and future new component will only be offered in SSIS 2010 and newer.
Officially Supported by Melissa#
Microsoft SQL Server 2017 - Microsoft Visual Studio 2017
SQL Server Data Tools for Visual Studio 2017 - https://docs.microsoft.com/en-us/sql/ssdt/download-sql-server-data-tools-ssdt?view=sql-server-2017#ssdt-for-vs-2017-standalone-installer
Microsoft SQL Server 2016 - Enterprise Edition and RC2 - Microsoft Visual Studio 2015
SQL Server Data Tools for Visual Studio 2015 (14.0.61021.0) - https://msdn.microsoft.com/en-us/mt186501.aspx?f=255&MSPPError=-2147217396
Microsoft SQL Server 2014 - Microsoft Visual Studio 2013
Microsoft SQL Server 2012 - Microsoft Visual Studio 2010/2012
Microsoft SQL Server 2010 - Microsoft Visual Studio 2008 - Deprecated
Microsoft SQL Server 2008 - Microsoft Visual Studio 2005 - Deprecated
Multiple SQL installations#
If you installed the components for one instance of SQL and are running another, you may have an older build or mismatched libraries and / or data files, which may result in sub optimal performance or component hanging.
If one version is installed and you attempt to create a project using another version, changing your SSIS component to run in compatibility mode will not ensure that the correct library is used at runtime.
SSIS Compatibility Issues#
There can be compatibility issues after installing the correct version of our components with respect to your configured installation of SSIS and SQL. See more at Known Issues.
64 bit Considerations for Integration Services#
The MatchUp processing engine is a 64 bit library. The SSIS front-end user interface is a 32 bit application. You can see this in the task manager. See the following link for an article of some of the 32 bit and 64 bit considerations.
64 bit installations? Running in 64 bit mode?#
The MatchUp processor is designed to run in 64 bit mode. Confirm that your configuration takes advantage in your project settings:
Project> Configuration > Run64BitRuntime = True
When processing takes place, open Task Manager – and confirm that you are running on 64 bit mode See this article on the simplest way to ensure your SSIS project is running in 64 bit mode.
Cannot Debug SSIS packages in 64 bit mode#
This link has an article showing an unsupported workaround.
Component Option FailedConfigurations#
Un-Needed Passthrough fields.
Golden Record/ Survivorship used.
Added Lookup stream process.
For these advanced configuration options, after the component has sorted the keys, deduped, and grouped the records, it will have to access all the cached temp file source data, and decide which columns to stream, roll-up, or use, to determine the golden record. All of which consume more processing time.
For source files with a large number of columns, we recommend that you configure your data source with a unique identifier and forego passing in columns that are unnecessary to the process. After processing is complete, canned ETL data tasks can easily use the unique identifier to link the Melissa results to the original data source record.
If the process requires only that all source records need to be streamed to output with a simple record disposition and group identifier, don’t configure Golden Record – the DupeGroup identifier and Result Code disposition are sufficient to query record groupings.
Data Considerations#
After making sure your environment is setup correctly to run MatchUp (Environment Evaluation Areas) and your matchcode has been evaluated and optimized (Matchcode Optimization) Users can still experience problems with slow processing speeds due to bad data.

In MatchUp, clustering is made possible when we have at least one component common to all used matchcode combinations. Since ZIP5 is used in all matchcode combinations, built keys will be grouped into different clusters based on that datatype. Therefore, if you have a database which contains uneven distribution of ZIP codes, as in the table below, changing your matchcode to include LAST NAME, for example, would create better clustering.
Table 1
RECID |
LAST NAME |
ADDRESS |
CITY |
ZIP |
|---|---|---|---|---|
1 |
Jones |
12 Main Street |
Boston |
02125 |
2 |
Smith |
57 Maple Lane |
Boston |
02125 |
3 |
Connor |
34 Summer Street |
Boston |
02125 |
4 |
Williams |
1 Oak Drive |
Boston |
02125 |
n |
*** |
*** |
*** |
02125 |
Table 2
In the case of Table 2, checking your data and an identifying an extensive amount of NULL values can also be a source of clustering issues. You can check this by using one of our Profiler products to check for NULL/Empty values, as well incorrect data types in columns. Passing your data through an address verification service in order to correct empty field values can help fix bad zip/addresses. For other NULL data types we suggest an alternate matchcode before deduping or splitting the data into multiple threads.
RECID |
LAST NAME |
ADDRESS |
CITY |
ZIP |
|---|---|---|---|---|
1 |
Jones |
12 Main Street |
Boston |
NULL |
2 |
Smith |
57 Maple Lane |
Boston |
NULL |
3 |
Connor |
34 Summer Street |
Boston |
NULL |
4 |
Williams |
1 Oak Drive |
Boston |
NULL |
n |
*** |
*** |
*** |
NULL |
Table 3
Table 3 shows a good example of data that has first been standardized and verified before processing with matchup. Due to the clustering aspect of ZIP codes, the data below will be grouped into two sections which will provide much better processing speeds.
RECID |
LAST NAME |
ADDRESS |
CITY |
ZIP |
|---|---|---|---|---|
1 |
Jones |
12 Main Street |
Boston |
02125 |
2 |
Smith |
57 Maple Road |
Boston |
02125 |
3 |
Connors |
3 Summer Circle |
Boston |
02121 |
4 |
Williams |
17 Oak Drive |
Boston |
02121 |
n |
*** |
*** |
*** |
*** |
Reference#
Public Library#
Powerpoints#
Case Studies/Whitepapers#
Benchmarking Files#
Tech Support#
Visit Tech Support Page